Яндекс выпустил крупнейший датасет для обучения беспилотных автомобилей прогнозированию

Яндекс
Яндекс разработал и опубликовал крупнейший датасет для обучения беспилотных автомобилей прогнозированию движений других машин и пешеходов. Он содержит в себе данные, эквивалентные 69 дням непрерывной езды и собранные в разных городах России, Израиля и США, а также в разную погоду: солнечную, дождливую и снежную. Компания выложила аналогичные датасеты для прогнозирования погоды и перевода, а также вместе с Оĸсфордсĸим и Кембриджсĸим университетами запустила конкурс по созданию прогнозирующих моделей, адаптирующихся к изменению условий по сравнению с обучающими данными. Подробнее о датасете можно прочитать в статье, доступной на arXiv.org, а сами данные опубликованы на GitHub и доступны для некоммерческого использования.

Алгоритмы, применяемые в беспилотных автомобилях, можно разбить на две большие группы, отвечающие за разные части вождения: восприятие среды (perception) и «логику». Алгоритмы восприятия среды берут данные с датчиков (как правило, камер, лидаров и радаров), объединяют их и составляют на их основе трехмерную карту окружающего пространства с распознанными объектами, такими как автомобили, границы дороги и другими. Разумеется, разработка и отладка этих алгоритмов — это сложная техническая задача, но в целом она успешно решается многими компаниями-разработчиками. Более сложная задача заключается в том, чтобы на основе карты объектов и истории их движения предсказать, как они будут вести себя дальше, а также проложить безопасный путь движения самого беспилотного автомобиля.
Разработчики беспилотных автомобилей Яндекса опубликовали крупнейший в мире датасет для обучения алгоритмов предсказания движения других машин и пешеходов. Они отмечают, что при создании датасета и конкурса руководствовались проблемой сдвига данных. Она заключается в том, что при обучении алгоритмов разработчики используют, как правило, большой и разносторонний набор данных, но он все равно не охватывает абсолютно все ситуации, которые могут возникнуть при его применении. В задаче беспилотного вождения это проявляется при езде в новом для алгоритмов городе, в котором водители ведут себя на дороге иначе, а также в редких и нестандартных погодных условиях. Разработчики задались целью решить две задачи: создать алгоритмы, устойчивые к попаданию в непривычные условия, а также способные качественно оценивать уверенность в своих решениях.
Датасет состоит из сцен, каждая из которых в свою очередь представляет собой карту окружающей среды с разметкой, нанесенных на карту моделей машин и пешеходов, светофоров с указанным для каждого момента времени сигналом, а также параметров подвижных объектов, то есть их траекторию, скорость и направление. Каждая сцена имеет длину 10 секунд и частоту 5 герц — то есть она состоит из статичных моментов езды, собранных каждые 0,2 секунды. Всего в датасете 600 тысяч таких сцен, собранных в шести городах: Москва, Сколково, Иннополис, Анн-Арбор (США), Тель-Авив (Израиль) и Модиин (Израиль). Стоит отметить, что 450 тысяч сцен собраны в Москве. Также в датасете размечен тип осадков: отсутствие осадков, дождь, снег и мокрый снег.

Распределение данных по городам и временам года
Andrey Malinin et al. / arXiv.org, 2021
Как и в других датасетах, данные поделены на обучающую, тестовую и валидационную части, однако деление сделано с важным отличием: разные группы содержат данные из разных городов и с разными осадками. Так разработчики предлагают проверять способность алгоритмов предсказания движений адаптироваться к отличию реальных ситуаций от тех, которые они встречали при обучении. Как и многие другие аналогичные датасеты, в том числе от Waymo, Lyft и Argo AI, датасет Яндекса доступен только для некоммерческого использования (под лицензией CC BY NC SA 4.0), поэтому его не смогут применять другие компании и команды разработчиков, не имеющие доступа к большому парку беспилотников.
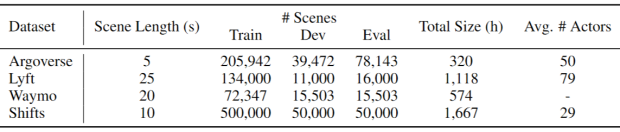
Сравнение с аналогичными датасетами
Andrey Malinin et al. / arXiv.org, 2021
Вместе с коллегами из Оксфордского и Кембриджского университетов разработчики Яндекса запустили конкурс Shifts Challenge, в рамках которого другие разработчики будут соревноваться в создании алгоритмов предсказания движения других машин и людей. Алгоритм должен на основе первых пять секунд сцены из датасета предсказать движение остальных объектов в следующие пять секунд, а также оценить уверенность предсказания. Создатели трех самых точных алгоритмов получат пять, три и одну тысячу долларов соотвественно занятым местам. Итоги конкурса будут подведены в конце ноября. Аналогичный конкурс и датасеты организаторы запустили для предсказания погоды и машинного перевода.
Помимо датасетов для логических алгоритмов у других компаний и организаций также есть и датасеты для распознавания окружающей среды. К примеру, такой датасет есть у Waymo, а для российских дорог его собрали организаторы конкурса Ice Vision, о котором мы рассказывали в материале «Кому на Руси водить хорошо».
Григорий Копиев
Он напоминает редактор внешности в видеоиграх
Ученые из США и Германии создали инструмент для редактирования объектов на изображении DragGAN. Он основан на нейросети, которая на лету генерирует новые изображения. Пользователь может отмечать мышкой разные элементы на фотографии, и они реалистично перемещаются, поворачиваются, растягиваются и уменьшаются — похожий подход нередко используют в видеоиграх для редактирования внешности персонажа. Препринт доступен на arXiv.org. В последние пару лет случился бум диффузионных нейросетей для генерации изображений по текстовым запросам — например, Stable Diffusion, DALL-E и Midjourney. Диффузионная модель умеет генерировать реалистичные изображения из случайного шума, а текстовое описание подсказывает модели, что именно должно быть на изображении. Но есть проблема: диффузионные нейросети недостаточно точны и не подходят, если нужно выполнить очень конкретную задачу при редактировании: сдвинуть объект на несколько пикселей в определенную сторону или повернуть его на определенное количество градусов. Задачу точного редактирования изображений можно решить с помощью других нейросетевых архитектур. Например, до появления диффузионных нейросетей часто использовали GAN — генеративно-состязательные сети. Такая модель состоит из двух нейросетей: генеративной и состязательной. По сути две нейросети соревнуются друг с другом: состязательная сеть учится отличать реальные изображения от сгенерированных, а генеративная, в свою очередь, пытается сгенерировать максимально реалистичные изображения из случайного шума (на этой идее основаны и диффузионные модели). Состязательная сеть посылает сигнал генеративной модели — сообщает ей, насколько реалистичное получилось изображение. И так до тех пор, пока генеративная сеть не научится обманывать состязательную. Группа ученых под руководством Кристиана Теобальта (Christian Theobalt) из Института информатики Общества Макса Планка придумала, как научить модель GAN делать сложные точечные изменения в изображении. Новый алгоритм называется DragGAN. Если пользователь хочет отредактировать какой-то объект на изображении, ему нужно отметить точками, где некоторые части объекта находятся до изменений и куда они должны переместиться после изменений. Например, чтобы повернуть мордочку кота на фотографии, нужно указать где сейчас находится нос и в какой точке он должен оказаться после поворота. Также можно отмечать область изображения, которая будет меняться. Главная задача DragGAN — реалистично трансформировать объект на изображении, опираясь на отмеченные пользователем точки до и после изменений. Она решается алгоритмом как задача оптимизации. Путь от каждой точки «до» к точке «после» разбивается на множество маленьких шагов. На каждом шаге генерируется новое изображение, которое совсем немного отличается от предыдущего. После каждого шага алгоритм определяет новые позиции точек «до», которые понемногу меняются в ходе оптимизации. Когда они совпадут с позициями «после», алгоритм завершит работу и пользователь получит последнее сгенерированное изображение. Обычно для одной операции редактирования требуется от 30 до 200 маленьких шагов, которые в сумме занимают несколько секунд. Модель обучали на нескольких датасетах с людьми (FFHQ, SHHQ), животными (AFHQCat), автомобилями (LSUN Car), пейзажами (LSUN, Landscapes HQ) и объектами под микроскопом (microscrope). Ее качество сравнили с похожей нейросетью UserControllableLT, которую авторы считают одной из лучших моделей для редактирования изображений с перемещением точек. На примерах видно, что DragGAN лучше определяет новое положение объектов и не делает лишних изменений. Также DragGAN сравнили с UserControllableLT на классической задаче по генерации изображений — трансформации ключевых точек лица. На изображении лица всегда можно выделить координаты точек, которые определяют его строение, мимику и положение на фото, в том числе контуры глаз, носа, губ. Модели получили изображения двух разных лиц и должны были изменить первое изображение так, чтобы ключевые точки на нем совпали или хотя бы максимально приблизились к ключевым точкам на втором изображении. Чем лучше совпадали два набора ключевых точек, тем точнее модели удавалось повторить мимику и положение второго лица, сохранив черты первого. Разница в координатах ключевых точек у DragGAN оказалась в 3 раза меньше, чем у UserControllableLT. Авторы утверждают, что DragGAN лучше своих предшественников справляется с изображениями, не похожими на тренировочную выборку, хотя иногда все равно допускает ошибки. Также она менее точно редактирует изображения, если выбранные начальные точки находятся в участках изображения, где мало текстур. Авторы обещали скоро выложить код DragGAN в открытый доступ, поэтому пользователи смогут сами протестировать, насколько хорошо она редактирует разные изображения. Раньше мы рассказывали, как другая нашумевшая нейросеть GPT-4 научилась работать с изображениями. Модель от компании OpenAI может понимать и изображения, и текст, хотя ответы по-прежнему выдает только в текстовом виде.