И целого интернета мало
Насколько высок риск инбридинга языковых моделей
В июле 2024 года в Nature вышла статья британских и канадских специалистов по искусственному интеллекту, которые задались вопросом: что произойдет с обучением нейросетей, когда интернет заполонят тексты, написанные другими нейросетями (а ждать уже недолго)? Ученые проанализировали, как современные языковые модели генерируют тексты, если и учатся на таких же сгенерированных текстах — и пришли к неутешительным выводам: языковые модели ждет вырождение. Но действительно ли стоит бить тревогу по поводу будущего генеративного искусственного интеллекта?

От транзисторов к трансформерам
Попытка сделать человеческий язык объектом вычислительной математики — одна из первых задач инженеров и ученых после появления в середине XX века достаточно мощных транзисторных вычислителей. Виновата отчасти была и холодная война: и США, и СССР были нужны эффективные средства машинного перевода с языка потенциального противника. Так зародилась компьютерная лингвистика — область на стыке математики, лингвистики и компьютерного моделирования, задачей которой стало описать естественные языки с помощью математических языковых моделей.
Элементарная задача языковой модели довольно понятная — вычислить для данной последовательности слов вероятность следующего. Еще Клод Шэннон в 1950 году предлагал решать эту задачу статистическими методами, то есть представить язык в виде распределений вероятности на множестве всех возможных предложений. Эти вероятности можно представить в форме деревьев решений, n-грамм или нейросетей с различной архитектурой. Главная сложность любой из них — подобрать набор вероятностей, соответствующий большому живому языку. С точки зрения математики построение модели сводилось к задаче оптимизации некоторой очень многомерной функции. Ни компьютеры, ни люди-расчетчики в 1950-е не были способны это сделать.
Ситуация изменилась в 1980-х, когда вычислительная техника стала значительно мощнее. Теперь с помощью компьютера можно было оптимизировать набор вероятностей таким образом, чтобы он был намного ближе к распределениям в реальном тексте. Это повысило точность языковых моделей для разных задач обработки естественного языка, в первую очередь машинного перевода. Компьютерная лингвистика стала в этот момент одним из направлений машинного обучения (machine learning, ML).
Очередная революция языковых моделей случилась уже в 2010-е. Во-первых, к этому времени компьютеры стали достаточно мощными, чтобы на них можно было запускать достаточно большие нейросетевые модели (подробнее про то, как устроены нейросети, мы рассказывали в материале «Зоопарк алгоритмов»). Во-вторых, стали в большом количестве появляться новые архитектуры нейросетей, и в 2017 году Google Brain и Google Research в статье «Attention Is All You Need», представил самую важную из них для языковых моделей — трансформер.
Оказалось, что эта архитектура быстрее обучается, точнее работает и лучше масштабируется, чем ее предшественник — рекуррентные нейронные сети. В итоге к концу десятилетия почти все крупные сервисы для машинного перевода, например Google Translate, перешли на трансформеры.
Больше чем языковые модели
Лучше всего трансформеры подошли для задачи генерации текста, напоминающего тот, на котором они обучались. Поскольку трансформеры довольно легко масштабировать, стало возможно сильно увеличивать число параметров в генеративных моделях. А чем больше нейросеть и чем больше в ней параметров, тем лучше текст она может сгенерировать: то есть текст на выходе становится все больше похож на исходный — и по грамматике, и по стилю. Самые успешные на сегодня большие языковые модели (large language model, LLM) стали генерировать текст, который часто неотличим от естественного.
Число параметров в этих моделях (а это, например, Llama от Meta AI*, Claude от Anthropic и GPT от OpenAI) превышает миллиард, но эта граница довольно условная: в отдельный класс эти модели выделяют скорее по качественным признакам. Эти языковые модели большие в том числе и потому, что они чуть больше, чем просто инструмент работы с текстом.
Язык — это не просто семантическая система, которая работает по определенным правилам; его логическая структура отражает онтологическую структуру мира. Поэтому и большая языковая модель, обучаясь и подстраивая сотни миллионов параметров, усваивает вместе с языком некоторые закономерности окружающей действительности (в ML-среде даже говорят, что большая языковая модель через поиск причинно-следственных связей внутри языка может построить свою модель мира). Из-за этого у нее часто появляются незапланированные навыки, которым их не обучали, например способность решать математические задачи.
Но этот сконструированный мир языковой модели — формальность. Никакого настоящего знания о мире — о том, что имеет место для человека, у модели нет. Поэтому ее высказывания могут быть ошибочны, могут быть неточны, могут быть просто бессмысленны. Но чем больше и качественнее датасет, на котором модель училась языку, тем более осмысленным и точным будут предложения в ее тексте после обучения. Точнее будут решения в том числе и неязыковых задач.
В зависимости от конкретной задачи и области, в которой планируется использовать языковую модель, требования к обучающему датасету могут быть разными. Например, при обучении универсальной LLM важны полнота датасета (то есть насколько вся необходимая информация присутствует в наборе данных) и его однородность (то есть насколько одинаково в разных частях датасета представлены те или иные слова и их комбинации), а если мы адаптируем модель под конкретную узкоспециальную задачу, на первый план выходят отсутствие нерелевантных, «мусорных» данных и их корректность.
Качественные данные для обучения модели, то есть разнообразные, однородные, полные и чистые от мусора (баланс между этими свойствами может смещаться в зависимости от задачи), — необходимый компонент для успешного применения машинного обучения, хотя и не достаточный: без оптимальных алгоритмов и мощных вычислителей ничего не получится. Но так или иначе, любой языковой модели нужна проверка качества.
Золотые буквы
Оказалось, что заранее предсказать, на каких данных лучше учить модели, не всегда легко. А поскольку хорошие данные часто тяжело найти, то они в итоге стали «новым золотом».
В случае с большими языковыми моделями данные — это много-много текстов. Казалось бы, проблем с ними быть не должно: по некоторым подсчетам в мире почти 160 миллионов книг, многие из которых оцифрованы. Однако все не так просто, как кажется.
Во-первых, все книги разные по стилю, языку, характеру заложенных в них знаний, поэтому, если мы хотим, чтобы модель была хороша в определенной предметной области, нужна фильтрация. Во-вторых, книги, даже документальные, не содержат всех знаний о мире, многие — подвергаются цензуре. Кроме того, стиль обучающего корпуса текстов может не подходить для задачи модели: к примеру, не получится сделать хороший чат-бот, если обучать модель на художественной литературе.
Чтобы языковые модели владели актуальным языком с актуальными данными, их обучают не только на книгах, но и на корпусах текстов из интернета, которые собирают в отдельные датасеты. «Например, один из первых и самых популярных корпусов для систем обработки естественного языка и обучения больших языковых моделей — это CommonCrawl — один из первых больших корпусов текстов из интернета для задач обработке естественного языка. Этот корпус, как один из самых полных, стал базой для создания прочих датасетов — например, с помощью обогащения или фильтрации.
В отличие от литературных корпусов, для датасетов из интернет-текстов всегда стоит вопрос отбора — среди страниц в сети огромное число текстов с ошибками разного характера. Поскольку CommonCrawl и подобные ему датасеты просто «пылесосят» интернет, то после этого данные с помощью незатейливых алгоритмов приходится фильтровать и исключать из корпуса страницы с бессмыслицей или техническими кодами. А, например, исследователи из OpenAI подошли к этому вопросу более творчески, когда обучали GPT-2 с 1,5 миллиарда параметров. Они собрали 40 гигабайт текста с восьми миллионов веб-страниц (для сравнения: в CommonCrawl на тот момент уже были петабайты данных и около 10 миллиардов страниц), найдя ссылки на них на Reddit. Авторы отбирали только те ссылки, посты с которыми получили не менее трех Шкала кармы на Reddit — это система оценки пользователей, которая показывает, насколько те активны и популярны. Карма формируется с помощью оценки постов и комментариев другими пользователями с помощью плюсов или минусов. Предполагается, что если пост или комментарий получает много очков кармы, то он в среднем более интересен и содержателен.
Стена данных
Начало 2020-х — время гонки между различными большими языковыми моделями, как открытыми, так и проприетарными. В этот период начался экстенсивный рост: масштабированию подвергалось как число параметров моделей, так и количество данных для обучения без существенных модификаций трансформерной архитектуры. Но довольно быстро у ученых стал «заканчиваться интернет»: большую часть доступных и подходящих для обучения текстов в датасеты уже включили, а новые в нужном для дальнейшего роста моделей количестве не появлялись.
Так, объем данных, использованных для обучения вышедшей в апреле 2024 года языковой модели Llama 3, составил 15 триллионов Токен — своего рода единица измерения объема текста в цифровой форме. Один токен примерно равен четырем символам. Для сравнения: длину английской версии романа «Война и мир» оценивают в 750 тысяч токенов.
Для более специализированных моделей, например, пишущих код, потолок уже достигнут: весь общедоступный код уже использован в обучении LLM и больше его взять негде. Леопольд Ашенбреннер, работавший ранее в OpenAI, оценивает объем текста всех публичных репозиториев на GitHub в несколько триллионов токенов и утверждает, что передовые модели уже обучены на большей части интернета. Эта проблема получила название стены данных (data wall). В эту стену в скором времени упрутся лаборатории, которые захотят получить еще более мощные языковые модели.
Проблему дефицита уникальных данных разработчики LLM предлагали решать самыми разными способами: повторно включать те же данные в обучающий датасет, использовать обучение с подкреплением, объединять текст с другими типами данных (звуком, изображениями, данными финансовых рынков и так далее), конвертировать данные из других областей или брать закрытые данные, например чаты в WhatsApp или неиндексируемые посты в Facebook*.
Но уже к 2023 году исследователи успели понять, что большинство этих методов не слишком эффективны: повторное включение тех же данных в обучающий датасет не приносит существенной пользы (раз, два) и плохо работает для нецелевых задач модели, а, например, мультимодальный подход — хоть и позволяет увеличить качество универсальных моделей, но не кратно. Поэтому многие исследователи, в том числе и сам Ашенбреннер, сходятся во мнении, что наиболее перспективный путь обхода стены — учить модели на синтетических данных.
От соборов к зайцам
Но обучение языковых моделей на данных, сгенерированных такими же моделями, — тоже не очевидно беспроигрышный вариант. Один из на первый взгляд веских аргументов против такого подхода появился в июле 2024 года в Nature. Авторы, исследователи из Англии и Канады во главе с братьями Ильей и Захаром Шумайловыми, пришли к понятным, но не самым очевидным выводам: обучение на синтетических данных приводит к деградации языковых моделей, и на практике этот процесс неизбежен.
Несмотря на то, что препринт статьи вышел примерно за год до публикации в Nature, статья стала довольно резонансной: это было первое академическое исследование на тему обучения моделей на синтетических данных, представленное на столь высоком уровне. И в период бума языковых моделей результаты показались на первый взгляд довольно пессимистичными.
Но так ли неутешительны выводы исследователей?
На самом деле ученые доказали довольно понятную вещь: если обучить модель на каком-то наборе данных, а затем сгенерировать с ее помощью новые, то статистические свойства начального и конечного наборов будут отличаться. И если повторять обучение многократно, то эти отличия будут накапливаться, а модель будет эволюционировать.
Сначала авторы доказали это теоретически. При этом их вывод относился не только к LLM, но и к другим типам моделей с другими типами данных (например, изображений). Применительно к текстам статистические свойства описывают вероятности встретить тот или иной токен в корпусе — то есть информацию о любых грамматических и стилистических паттернах, которые должны улавливать LLM.
Ученые показали, что при многостадийном обучении модель начинает дискриминировать редкие события (например, определенное сочетание слов, букв или какой-либо иной текстовый паттерн) и повышает встречаемость типичных. В итоге вероятность этих редких событий (хвостов распределений) уменьшается на каждом шаге, стремясь в пределе к нулю.
Следовательно, если использовать только что синтезированные тексты в качестве обучающего датасета для еще не обученной копии той же модели, то качество генерации будет ухудшаться с каждым следующим поколением — нейросеть, согласно рассуждениям, должна в итоге порождать нерелевантные или бессмысленные результаты. Авторы назвали такую деградацию коллапсом модели. Коллапс чреват тем, что нейросеть перестанет улавливать нюансы.
Чтобы подтвердить свои выводы, ученые провели серию экспериментов. Для этого они подготовили датасет на основе статей из Википедии, написанных человеком, и обучили на нем небольшую опенсорсную LLM — включающую Тут важно сделать две оговорки. Во-первых, формально по числу параметров это довольно далеко от большой языковой модели. Но свой выбор авторы мотивировали тем, что в противном случае пришлось бы затратить очень много электроэнергии (и произвести очень много углекислого газа) и времени. Во-вторых, не до конца понятно, как переносить выводы работы на модели других размеров. И несмотря на то, что авторы делают предположения на этот счет, системной проверки величины эффекта от размера модели они не проводили.
На каждом шаге авторы следили за тем, как у модели меняется распределение перплексии — одной из внутренних статистических метрик, по которой можно оценить качество модели. Оказалось, что коллапс, как и предсказывала теория, действительно имеет место, когда датасет полностью синтетический. Но если хотя бы десять процентов датасета остаются написанными человеком, этот эффект практически исчезает.
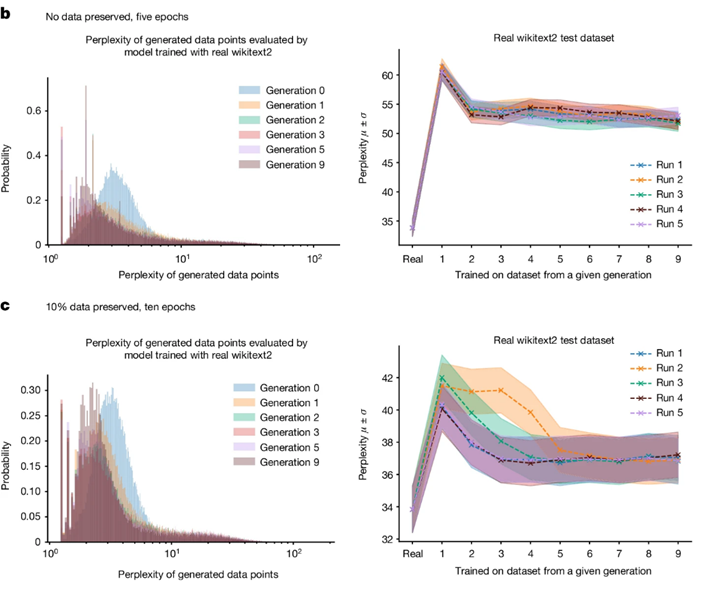
За эволюцией модели авторы следили только по изменению ее внутренних метрик. Какого-то внешнего параметра, который характеризовал бы деградацию сгенерированных данных, ученые не использовали (по крайней мере не привели его в статье). Зато они проиллюстрировали коллапс модели примерами текстов, которые генерировали модели разных поколений.
Модель нулевого поколения, которая обучалась на датасете текстов из Википедии — то есть по сути на человеческих текстах, — генерировала свой датасет, который содержал довольно мало ошибок. Вот отрывок из текста, который написала модель нулевого поколения (пунктуация и орфография сохранены):
Примерный перевод: Архитектура эпохи Возрождения, например собор Св. Иоанна в Лондоне. Самый ранний сохранившийся пример архитектуры Перпендикулярного Возрождения найден в церкви Богоматери Гернси XVIII @-@века, которая датируется концом XIX века. Существует два типа перпендикулярных церквей : те.
Исследователи пишут, что отрывок был сгенерирован под влиянием статьи на Википедии про здания в графстве Сомерсет. На самом деле тут есть хитрость: выдача модели нулевого поколения опирается, конечно, не на эту конкретную статью в Википедии, а на все сразу, а также на корпусы текстов, на которых предобучали модель перед тем, как с ней стала работать группа Шумайловых. Так или иначе, соответствие этого отрывка из сгенерированного текста и статьи на Википедии — довольно условное. Цель подобного сравнения — не проиллюстрировать искажение смысла, а дать читателям возможность оценить изменение качества текста.
Сравнивать содержание текста после девяти поколений обучения уже невозможно в принципе. Самый «похожий» на статью в Википедии про здания в Сомерсете кусок текста — полная тарабарщина:
Примерный перевод: архитектура. Помимо того, что это место обитания для некоторых из крупнейших в мире популяций черно @-@ хвостых зайцев, бело @-@ хвостых зайцев, сине @-@ хвостых зайцев, красно @-@ хвостых зайцев, желто @-
Аналогичный эффект авторы получили не только с текстовыми моделями, но и на других архитектурах: вариационных автокодировщиках (Variational autoencoder, VAE) и моделях гауссовых смесей (Gaussian Mixture Model, GMM) — модели, которые часто применяют для генерации и классификации изображений соответственно.
Ученые уверяют (не приводя, правда, экспериментальных доказательств), что, если модель будет больше, а синтетические данные она получит еще на этапе предобучения, а не файнтюна, то коллапс будет еще более выраженным, чем они увидели на сравнительно небольшой модели. А это грозит серьезными проблемами в будущем, когда количество сайтов, наполненных синтетическими текстами, существенно превысит число обычных, «человеческих» текстов. При этом компании, которые успели обучить свои модели до этого момента, по мнению авторов исследования, могут получить «преимущество первопроходца»: их качество останется непревзойденным навсегда.
Не все то золото
Помимо журналистов самого Nature, исследованием в июле 2024 года заинтересовались крупные издания: The Financial Times, Forbes и Bloomberg. Эксперты и журналисты часто использовали сравнение деградации моделей с близкородственным скрещиванием у животных или инбридингом. Как и в ситуации с коллапсом ИИ-моделей, в таком потомстве резко уменьшается генетическое разнообразие, из-за чего накапливаются опасные мутации и снижается жизнеспособность.
Этот хайп, правда, к лету 2024 года уже успел несколько потерять актуальность. Еще в 2023 году, когда Шумайловы с коллегами опубликовали препринт статьи, о работе написали, например, TechTarget или Scientific American, а на момент написания этого текста на сам препринт сослались больше 200 раз. «Учитывая, что препринт статьи вышел на Arxiv.org год назад, публикацию в Nature можно считать несколько устаревшей, — считает Рыков. — Процесс публикации в хорошем рецензируемом журнале может затянуться, поэтому существуют сервисы типа Arxiv, которые позволяют „занять“ за собой место. Поэтому если и стоило бить тревогу, то уже как около года назад».
В течение всего 2023 года исследователи из других групп сообщали о похожем эффекте в моделях для рисования изображений: на базе генеративно-состязательных сетей (generative adversarial network, GAN) и диффузионных моделей (diffusion based models). А американские ученые обнаружили крайне высокую уязвимость к коллапсу у одной из самых популярных опенсорсных моделей Stable Diffusion: изображения начинают портиться, как только доля обучающего датасета, сгенерированного ИИ, становится больше всего трех процентов.
Но несмотря на то, что с этой проблемой ученые знакомы уже какое-то время, менее важной она не становится. Эксперты предсказывают, что к 2026 году до 90 процентов контента в интернете будет сгенерировано ИИ. Однако, например, научный сотрудник лаборатории Fusion Brain в Институте AIRI Антон Разжигаев в разговоре с N + 1 выразил сомнение в строгой необходимости именно «чистых» данных в интернете: «Ошибок, опечаток, неточностей и прочей „грязи“ в естественных текстах еще больше, чем в текстах, сгенерированных искусственным интеллектом — и для них уже есть методы фильтрации по источнику/дате/метаданным и тому подобному. Точно так же можно отслеживать и долю сгенерированного контента — не сказать, что это катастрофа».
Проблема, по сути, сводится к тому, чтобы научиться детектировать машинно-сгенерированный текст — тогда исключая его, можно оставлять искусственный текст только в том количестве, которое не портит потом выдачу модели. Но и создание такого детектора — пока предмет научной дискуссии. И хотя существует мнение, что это невозможно, каждый год появляются новые подходы к этой проблеме — некоторые из них менее успешные, какие-то (например, топология представлений данных) уже сейчас неплохо работают. А не так давно стало известно, что у OpenAI есть инструмент на основе технологии водяных знаков, в котором компания уверена на 99,9 процента, — пока, правда, разработчики опасаются запускать его на серверах и делать общедоступным.
Но даже если создать идеальный детектор сгенерированного текста невозможно, это не станет проблемой. «В возможность создания достоверного детектора любых ИИ-текстов я не верю, — признается Разжигаев. — Но зато верю, что можно детектировать „низкокачественный“ сгенерированный текст, и поэтому какой-то генеративный мусор обнаружить получится. А то, что обнаружить не получится, — оно достаточно качественное, чтобы не портить обучение LLM».
Конечно, удаление из датасетов только самого низкокачественного сгенерированного текста не полностью спасает от искажения статистических распределений в новом тексте. Поэтому этот язык новых текстов будет статистически немного отличаться от живого языка книг и переписок. Но с другой стороны, это только отчасти проблема машинного обучения. Статистические метрики текста меняются и при автоисправлениях, и просто от смены узуса при перемещении коммуникаций в цифровое пространство (подробнее про то, как компьютерное общение повлияло на грамматику повседневного общения, читайте в материале «Точки мои точки.»). «Качество данных после повсеместного распространения доступных редакторов и спеллчеккеров только выросло, — резюмирует Разжигаев. — Размытие распределений — это важный вопрос, но уровень этой проблемы не настолько большой, чтобы переживать. Это просто новая реальность, исходя из которой нам придется работать».
Мало ли?
Иногда обучение языковых моделей именно на синтетических данных не просто не портит модель, а наоборот — приносит дополнительную пользу. Например, в эти данные не может случайно попасть конфиденциальная или чувствительная информация. Кроме того, используя в обучающем датасете сгенерированные тексты, можно менять «репрезентативность» данных, смещая баланс в ту или иную сторону. При этом искусственные тексты в датасете могут не дублировать естественные функционально, а дополнять их. Например, в диалоговых датасетах часто первые реплики человеческие — это могут быть реальные вопросы с форумов, — а ответы и прочие реплики уже дописывает модель.
Так или иначе, сейчас большую часть обучающих датасетов, на которых крупные компании дообучают современные модели, составляют именно сгенерированные искусственным интеллектом данные. Так делают и Meta AI*, выпустившая в июле 2024 года Llama 3.1, и Microsoft, которая в августе 2024 года представила Phi-3.5-vision. А использование текстов, написанных передовыми моделями, способно, в свою очередь, приблизить качество более дешевой модели к качеству дорогой проприетарной. В конце концов, даже по результатам исследований Шумайловых всего 10 процентов «человеческих» текстов сильно уменьшают деградацию, а это — вполне доступная цифра.
Поэтому говорить о том, что мир прикладного искусственного интеллекта ждут какие-то существенные изменения из-за массового перехода на синтетику, кажется, пока рановато.
* Facebook принадлежит компании Meta, деятельность которой в России запрещена.
Что такое нейросети и какими они бывают
Всего за пару десятков лет нейросети, кажется, научились всему: от генерации текста и изображений до прогноза погоды, вождения автомобилей и обнаружения патологий на рентгеновских снимках. Тем не менее, в отличие от нашего мозга, созданные по его подобию инструменты неуниверсальны — для решения конкретных задач нейросети постоянно изменяют и совершенствуют. Рассказываем, как они устроены, чем отличаются друг от друга и почему ни одна нейросеть не способна обойтись без человека.